
以数据文件“马克威通用数据1.mkw”为例,演示RBF神经网络算法的操作过程。首先,在工作区内,打开建模分析工作流:“机器学习”→“神经网络”→“RBF神经网络”,接着选择模型的训练或应用,然后选择数据源,设置算法参数,最后双击运行按钮。
具体操作如下:
(1)模型训练
设置好目标变量和输入变量,且把隐含层中心个数设置为输入变量个数的2倍或2倍以上,选择训练模型文件的保存路径,如下图所示:
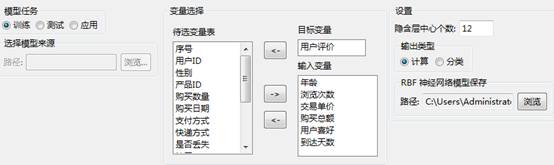 RBF神经网络-属性设置
RBF神经网络-属性设置
选项说明
目标变量:需要预测的变量。
输入变量:与所预测的对象有关的变量。
隐含层中心个数:设定模型的隐含层中心数。
模型保存:选择模型保存的路径。
双击“运行”节点输出结果如下:
 RBF神经网络预测-树形结果列表
RBF神经网络预测-树形结果列表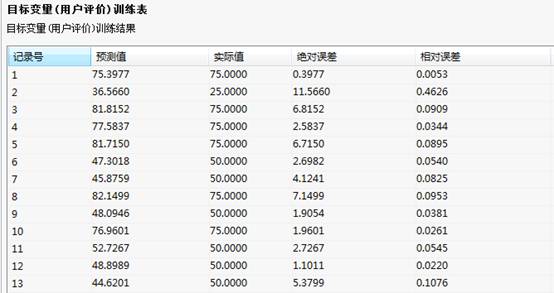 RBF神经网络-目标变量训练结果
RBF神经网络-目标变量训练结果
结果说明
当隐含神经层中心数设置为2倍以上时,预测值和目标值几乎重合在一起,经过训练和结果比较,认为训练结果误差是可以接受的。
当有成百上千个特征量要输入的时候,神经网络效果就不是很好,可能导致长时间“训练”,而且不会收敛于好的结果。这时,就要把神经网络和决策树结合起来使用,因为决策树擅长为训练神经网络选择最重要的变量。
(2)模型应用
完成模型训练后,可以应用模型对数据进行预测分析,选择“模型应用”标签,并选择模型训练时保存的模型路径来源,将模型变量与数据变量进行匹配,如下图:
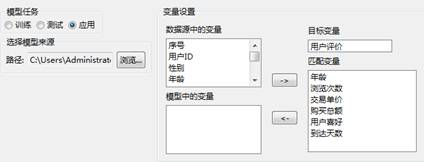 RBF神经网络-属性设置
RBF神经网络-属性设置
选项说明
模型来源:选择训练得到的模型,以进行预测应用。
变量设置:匹配模型中的变量和数据源中的变量。当加载模型文件后,
系统会自动根据数据文件和模型文件进行同名匹配。用户也可以根据实际的需要,自定义匹配变量。
运行的结果如下:
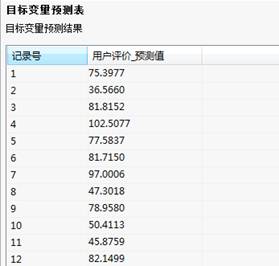 RBF神经网络-目标变量预测结果
RBF神经网络-目标变量预测结果
特征要求:输入变量和目标变量应该存在因果决定关系,而非毫无关联的随机数据,亦即目标变量应是“可预测”的。
类型要求:输入样本数据需为数值型,整型或浮点型皆可。
完整要求:计算时程序对样本数据缺失值自动填零。
大小要求:为了充分训练参数,样本数据不宜小于输入变量个数的20倍。
RBF神经网络能够逼近任意的非线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度,已成功应用于非线性函数逼近、时间序列分析、数据分类、模式识别、信息处理、图像处理、系统建模、控制和故障诊断等。
RBF神经网络是一种三层前向网络,通过输入层空间到隐含层空间的非线性变换以及隐含层空间到输出层空间的线性变换,实现输入层空间到输出层空间的映射。这两个层间变换参数的学习可以分别进行,使得RBF神经网络的学习速度较快且可避免局部极小问题。
RBF(Radial Basis
Function,径向基函数)是某种沿径向对称的标量函数,通常定义为空间中点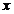 到某一中心
到某一中心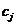 之间欧氏距离的单调函数,最常用的径向基函数是高斯函数,形式为:
之间欧氏距离的单调函数,最常用的径向基函数是高斯函数,形式为:
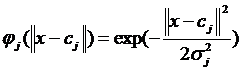
其中为函数中心向量, 为宽度向量。高斯函数的作用域表现出局部性,即当远离时函数取值较小。
为宽度向量。高斯函数的作用域表现出局部性,即当远离时函数取值较小。
如下图所示,RBF神经网络的结构从左至右分为三层,依次是输入层、隐含层和输出层:
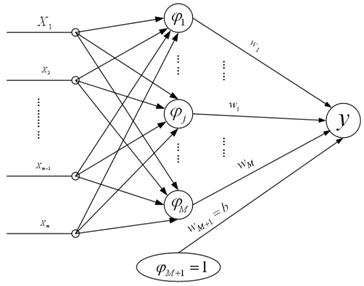 RBF神经网络结构图
RBF神经网络结构图
网络的输出如下式所示:
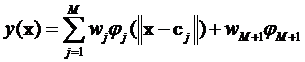
与BP神经网络类似,理论上RBF神经网络对任何非线性连续映射能够用任意精度近似。但RBF神经网络有其自身的特点:
RBF神经网络结构的物理意义比较明确。RBF网络可以看成是输入层数据空间(通常是低维空间)到隐含层空间(通常是高维空间)的一种非线性映射,以及隐含层空间到输出层的线性映射。通过选择适当的非线性映射变换RBF函数,从而将原低维空间非线性可分的问题转换成高维空间的近似线性可分的问题。
RBF神经网络的学习分成两阶段,自组织学习阶段和监督学习阶段。在自组织学习阶段获取隐含层中心,在监督学习阶段获取隐含层到输出层之间的权值,各部分参数都可以快速学习,因此速度较快。
分阶段学习的RBF神经网络无局部极小值问题。由于RBF神经网络的学习与输入样本聚类中心密切相关,因此RBF神经网络比较适合应用于有类别特征的数据。
模型隐含层中心个数设定原则:
由于RBF神经网络的思想是将低维空间非线性可分问题转换成高维空间线性可分问题,因此隐含层中心个数应该大于输入变量个数,一般设为输入变量个数的2倍以上。
由于隐含层中心点坐标代表了输入数据的聚类中心,因此隐含层中心个数应该大于输入数据集的按记录划分的类别个数,这样才能有效提取各种类别输入数据的特征。这需要对输入数据集的业务特征有一定了解,然后给出输入数据类别个数的大致范围。一般设隐含层中心个数为输入数据类别个数的2倍以上。
综合以上两个原则设定隐含层中心个数,然后可以根据训练和测试的效果,对中心个数进行适当调整。一般情况下,中心个数设得越多,训练的效果越好,但所需要的时间越长;而当中心个数多到一定程度的时候,增多中心个数对训练效果的改善已不大。另外,隐含层中心数应该不大于训练数据记录数。
输出结果:
目标变量训练表:目标变量训练结果。
目标变量预测表:目标变量预测结果。
| 订购用户 | 订购时间 | 年限 | 运行环境 | 版本 |
| 1381****064 | 2026-03-09 10:21:21 | 1年 | Windows | 单机版 |
| 1357****252 | 2024-01-11 15:46:13 | 1年 | Windows | 单机版 |
| 1786****815 | 2023-03-10 14:06:42 | 1年 | Windows | 单机版 |
| 1887****720 | 2022-11-21 14:34:37 | 1年 | Windows | 单机版 |
| 1590****469 | 2021-09-22 14:23:40 | 1年 | Windows | 单机版 |
| 1563****375 | 2021-05-28 17:34:55 | 1年 | Windows | 单机版 |
| 1836****680 | 2021-05-14 21:00:00 | 1年 | Windows | 单机版 |
| 1373****472 | 2021-04-14 17:34:54 | 1年 | Windows | 单机版 |
| 1373****472 | 2021-04-14 17:29:16 | 1年 | Windows | 单机版 |
| 1864****834 | 2021-01-26 12:28:18 | 1年 | Windows | 单机版 |

 加入购物车成功!
加入购物车成功!
