
以数据文件“马克威通用数据1.mkw”为例,演示多维关联规则算法的操作。数据显示症状与流感之间的统计信息。通过这些数据进行关联规则分析。首先,在工作区内,打开建模分析工作流:“机器学习”→“关联规则”→“多维关联规则”,接着选择数据源,然后设置算法参数,最后双击运行按钮。
设置参数界面如下图所示,目标变量为“流感”,输入变量为“头痛”、“肌肉痛”、“体温”,最小支持度为10%,最小置信度为50%:
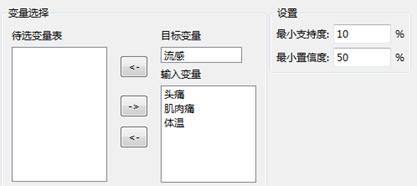 多维关联规则-属性设置
多维关联规则-属性设置
选项说明
变量选择:设置模型的变量。
最小支持度:设置规则提取的最小支持度。
最小置信度:设置规则提取的最小置信度。
双击“运行”节点,系统进入计算过程,并在计算阶数后显示结果:
 多维关联规则-树形结果图
多维关联规则-树形结果图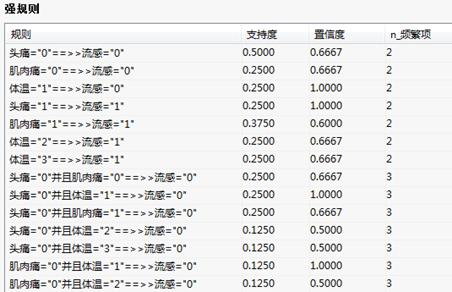 多维关联规则-强规则
多维关联规则-强规则
输入要求:数值型。
关联规则(Association Rules)是数据挖掘的主要技术之一,用于从庞大的数据库中寻找有用或有趣的模式和规则。除此之外,关联规则分析方法还可用于诸多领域,如网络日志分析,预警系统等。
单维关联规则研究的基本上都是同一个字段的值之间的关系,比如用户购买的物品。用多维数据库的语言就是单维或者叫维内的关联规则,这些规则一般都是在交易数据库中挖掘的。但是对于多维数据库而言,还有一类涉及到多个属性或谓词的规则称为多维关联规则。
例如:年龄(X,“20...30”)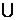 职业(X,“学生”)==> 购买(X,“笔记本电脑”)
职业(X,“学生”)==> 购买(X,“笔记本电脑”)
在这里我们就涉及到三个维上的数据:年龄、职业、购买。根据是否允许同一个维重复出现,可以又细分为维间的关联规则(不允许维重复出现)和混合维关联规则(允许维在规则的左右同时出现)。
年龄(X,“20...30”)购买(X,“笔记本电脑”)==> 购买(X,“打印机”)这个规则就是混合维关联规则。
在挖掘维间关联规则和混合维关联规则的时候,还要考虑不同的字段种类:种类型和数值型。对于种类型的字段,原先的算法都可以处理。而对于数值型的字段,需要进行一定的处理之后才可以进行。
处理数值型字段的方法基本上有以下几种:
1)数值字段被分成一些预定义的层次结构。这些区间都是由用户预先定义的。得出的规则叫做静态数量关联规则。
2)数值字段根据数据的分布分成了布尔字段。每个布尔字段都表示一个数值字段的区间,落在其中则为1,反之为0。这种分法是动态的。得出的规则叫布尔数量关联规则。
3)数值字段被分成一些能体现它含义的区间。它考虑了数据之间的距离因素。得出的规则叫基于距离的关联规则。
4)直接用数值字段中的原始数据进行分析。使用一些统计的方法对数值字段的值进行分析,并且结合多层关联规则的概念,在多个层次之间进行比较从而得出一些有用的规则。得出的规则叫多层数量关联规则。
输出结果:
多维关联规则:列出频繁项集和强规则。
| 订购用户 | 订购时间 | 年限 | 运行环境 | 版本 |
| 1786****815 | 2023-03-10 14:12:48 | 1年 | Windows | 单机版 |
| 1803****455 | 2019-04-05 12:07:11 | 1年 | Windows | 单机版 |
| 1361****169 | 2019-04-01 17:30:32 | 1年 | Windows | 单机版 |
| 1803****455 | 2019-03-30 10:06:15 | 1年 | Windows | 单机版 |
| 1801****427 | 2019-02-18 19:07:33 | 1年 | Windows | 单机版 |
| 1803****455 | 2019-01-14 14:04:56 | 1年 | Windows | 单机版 |
| 1381****637 | 2019-01-10 20:33:51 | 1年 | Windows | 单机版 |
| 1886****092 | 2018-09-02 10:13:17 | 1年 | Windows | 单机版 |
| 1563****680 | 2018-08-21 13:41:16 | 1年 | Windows | 单机版 |
| 1811****398 | 2018-07-23 13:13:07 | 1年 | Windows | 单机版 |

 加入购物车成功!
加入购物车成功!
