
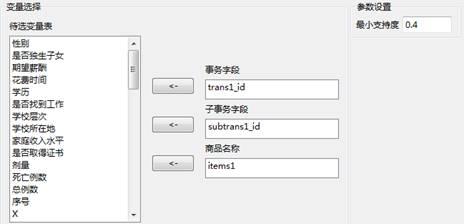
(1)以数据文件“马克威通用数据3.mkw”为例,演示PrefixSpan算法的操作。首先,在工作区内,打开建模分析工作流:“机器学习”→“PrefixSpan序列模式”,接着选择数据源,然后设置算法的参数,最后点击运行按钮。
其中各类参数的含义为:
事务字段:选择需要分析的事务字段
子事务字段:选择需要分析的子事务字段
商品名称:需要分析的商品的分类字段
最小支持度:需用户自行设定,默认数值为0.4
设置好参数如下所示:
(2)输出结果
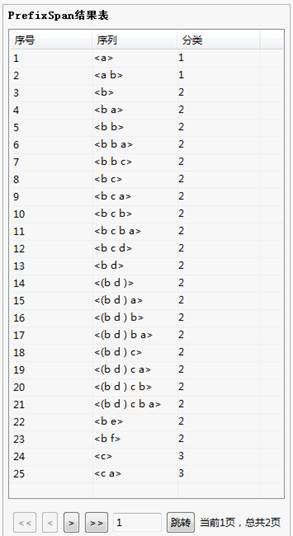
(3)结果说明
按照算法要求,把序列的序号分类结果展现如上表。
输入数据类型:数值型数据、字符型数据。(要求输入的数据应满足序列的模式)
PrefixSpan在序列事务及有关信息处理中有着广泛的应用,如客户购物习惯、Web访问模式、科学实验过程分析、自然灾害预测、疾病治疗、药物检验及DNA等。
PrefixSpan算法的原理是采用后缀序列转前缀序列的方式来构造频繁序列的,在转换过程中,从后缀序列中提取出1项加入到前缀序列中,变化的规则就是从左往右扫描,找到某元素的对应的项,然后做出改变;根据此规则,继续递归,直到后续的序列不满足最小支持度阈值的情况。
PrefixSpan是一种不需要产生候选集的频繁模式挖掘方法,采用分治的思想,不断产生序列数据库的多个更小的投影数据库(后缀子序列),然后在各个投影数据库上进行序列模式挖掘。
输出结果:可以实现事务集的序列分类问题。
| 订购用户 | 订购时间 | 年限 | 运行环境 | 版本 |
| 1786****815 | 2023-03-10 14:06:42 | 1年 | Windows | 单机版 |
| 1506****429 | 2021-03-08 15:46:47 | 1年 | Windows | 单机版 |
| 1801****846 | 2019-05-23 16:35:18 | 1年 | Windows | 单机版 |
| 1801****427 | 2019-02-18 19:07:33 | 1年 | Windows | 单机版 |
| 1864****834 | 2018-09-25 15:47:28 | 1年 | Windows | 单机版 |
| 1811****398 | 2018-07-23 13:08:55 | 1年 | Windows | 单机版 |
| 1580****630 | 2018-07-17 10:05:56 | 1年 | Windows | 单机版 |
| 1801****513 | 2018-04-07 13:53:02 | 1年 | Windows | 单机版 |
| 1398****856 | 2018-01-05 22:43:24 | 1年 | Windows | 单机版 |
| 1398****856 | 2018-01-05 22:35:31 | 1年 | Windows | 单机版 |

 加入购物车成功!
加入购物车成功!
