
(1)以数据文件“马克威通用数据3.mkw”为例,演示Birch算法的操作。首先,在工作区内,打开建模分析工作流:“机器学习”→“BIRCH”,接着选择数据源,然后设置算法的参数,最后点击运行按钮。
其中各类参数的含义为:
内部节点平衡因子:又叫枝平衡因子,用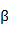 表示,用来控制非叶节点数。
表示,用来控制非叶节点数。
叶节点平衡因子:又叫叶平衡因子,用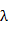 表示。
表示。
簇直径阀值:用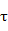 表示,用来限制叶节点的子簇的大小。
表示,用来限制叶节点的子簇的大小。
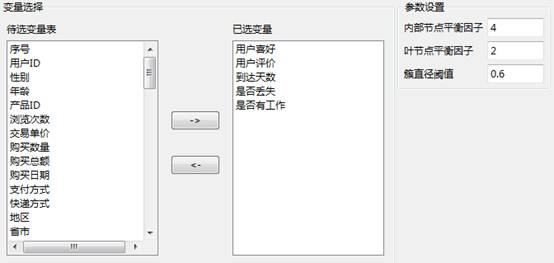
选择变量“用户喜好”、“用户评价”、“到达天数”、“是否丢失”、“是否有工作”进行聚类分析。具体的参数设置如下所示:
(2)输出结果
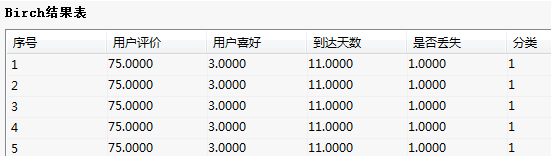
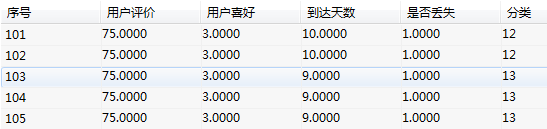
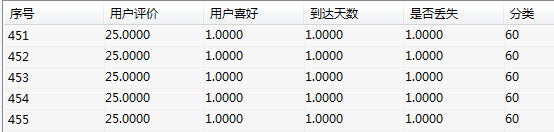
(3)结果说明
从分析结果可以看出,按照不同层次,不同属性进行了分类,用户购买商品,按照用户体验,客户喜好,达到天数,是否丢失,来进行聚类后评判用户群体的特征。
输入变量类型:数值型
Brich算法是一种层次聚类算法,主要应用于对样本数据进行聚类。由于引入簇结构,能够克服一般聚类的不可伸缩性和扩展性,使得该聚类方法在大型数据库中取得好的速度和伸缩性。
Brich算法已经在实际领域中得到广泛的应用,包括市场研究、模式识别、数据分析和图像处理。在商务中,可以用来发现不同的顾客群,刻画顾客的特征;在生物学中,能够用来推到动植物分类等。
Birch是一个综合的层次聚类算法,既能对大规模数值数据进行聚类,又能够有效地处理离群点。Birch算法只需扫描一遍数据库就可以得到一个好的聚类效果,而且不需事先设定聚类个数,克服了K-Means算法需要预先设定聚类中心点个数的缺点。
BIRCH聚类是通过聚类特征树(ClusterFeature-Tree)实现的,在一定程度上保存了对数据的压缩。通过引入聚类特征和聚类特征数来概括簇,这种簇结构使得该方法在大型数据库中取得好的速度和伸缩性,对对象的增量和动态聚类也非常的有效;由于Birch算法使用半径或直径的概念来控制簇的边界,比较适合球形的簇,如果簇不是球形的,则聚簇的效果将受到影响。
该算法在进行聚类时,一般包含两个步骤:1)单遍扫描数据,建立一颗存放于内存的初始CF树;2)采用某个选定的聚类算法对CF树的叶节点进行聚类,把稀疏的簇作为异常点删除而把稠密的簇合并为更大的簇。
一般的簇的质心X0,半径R和直径D可如下定义:


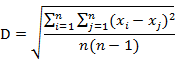
其中R是对象到质心的平均距离,D是簇中成对的平均距离。R和D都反映了质心周围簇的紧凑程度。
输出结果:
从结果可以看出,Brich算法是一种层次聚类算法,主要用于对数据进行聚类,该算法客服了一般聚类的不可伸缩性和扩展性,使得该聚类方法在大型数据库中取得好的速度和伸缩性。
| 订购用户 | 订购时间 | 年限 | 运行环境 | 版本 |
| 1381****064 | 2026-03-09 10:21:21 | 1年 | Windows | 单机版 |
| 1381****064 | 2023-11-20 10:45:45 | 1年 | Windows | 单机版 |
| 1891****615 | 2023-06-26 10:01:45 | 1年 | Windows | 单机版 |
| 1786****815 | 2023-03-10 14:06:42 | 1年 | Windows | 单机版 |
| 1590****469 | 2022-09-23 15:01:08 | 1年 | Windows | 单机版 |
| 1590****469 | 2021-09-22 14:23:40 | 1年 | Windows | 单机版 |
| 1778****312 | 2020-04-24 10:03:38 | 1年 | Windows | 单机版 |
| 1580****348 | 2020-04-20 13:10:48 | 1年 | Windows | 单机版 |
| 1586****746 | 2020-04-10 09:19:32 | 1年 | Windows | 单机版 |
| 1365****905 | 2019-05-24 01:09:09 | 1年 | Windows | 单机版 |

 加入购物车成功!
加入购物车成功!
