
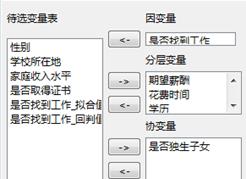
(1)以数据文件“马克威通用数据3.mkw”,演示有序回归算法的操作说明。因变量选择“是否找到工作”,分层变量选择“期望薪酬”、“花费时间”、“学历”、“学校层次”,协变量选择“是否独生子女”。
在工作区,打开建模分析工作流“高级统计”→“回归分析”→“有序回归”,接着选择数据源,然后设置算法的参数。其中各类参数的含义如下:
因变量:选入有序多分类的因变量。
分层变量:用于选入分类自变量,可以是有序或无序多分类,系统会自动为它们生成哑变量。
协变量:用于选入连续型的自变量。
参数设置,如下所示,因变量设置为“是否找到工作”,协变量设置为“是否独生子女”,分层变量设置为“期望薪酬”、“花费时间”、“学历”、“学校层次”:
(2)输出结果:

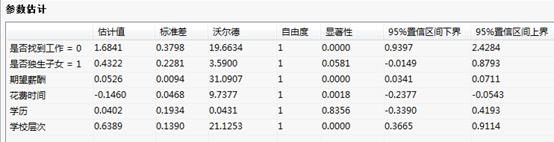
参数估计:
模型拟合信息:

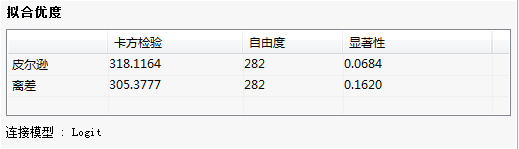
拟合优度:
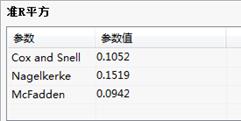
准R平方:
(3)结果说明:
参数估计表给出系数估计及其他各类统计量,模型拟合信息表列出的是总模型的似然比检验结果。拟合优度表给出皮尔逊检验和方差检验。准R平方表给出伪决定系数的大小。
输入变量类型:整型、浮点型
(注:因变量是一列整型数,且每个数据要求有一定重复;协变量是实数;因变量和协变量可以有多个变量)
输入数据尺度:标量型
有序回归用于研究某一随机事件发生的概率与多维序数变量之间的关系。能对因变量的各个等级拟合相应的模型,得到模型中与之对应的频率和累积频率、频率和累计频率的Pearson残差、观测和期望概率、因变量的观测和期望累计概率、估计参数的相关矩阵和协方差矩阵等统计量,被广泛地应用于需要对有序数据进行回归分析的各个领域,如医药卫生、生物、化学等。
有序回归对反应变量的各类中有明确的排序,但相邻两类之间的差距未知的情况下,这时就需要用到有序模型,最常见的是有序Logistic模型:
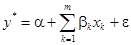
其中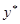 表示观测现象内在趋势,它并不能被直接测量,
表示观测现象内在趋势,它并不能被直接测量,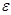 为误差项。
为误差项。
当实际反应量有J种类别时,相应取值为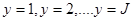 并且各取值之间的关系为
并且各取值之间的关系为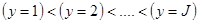 ,那么共有
,那么共有 个未知门槛或分界点将各相邻类别分开,即
个未知门槛或分界点将各相邻类别分开,即
若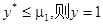
若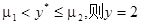
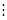
若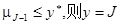 。
。
其中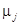 为分界点,有J-1个值,且有
为分界点,有J-1个值,且有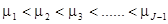 。
。
给定X值的累积概率可以按下式表示:
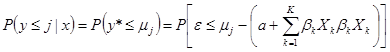
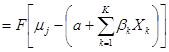
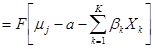
式中F(*)为函数。
J:有序反应的个数;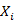 :观测的自变量组成的向量;
:观测的自变量组成的向量;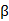 是自变量的系数估计。
是自变量的系数估计。
输出结果:
参数估计: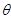 (模型中的门槛值)和
(模型中的门槛值)和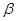 (自变量的系数估计)、标准误差、Wald统计量、自由度、显著性概率和95%自信区间的上下界。其中越大则该变量效果越显著;
(自变量的系数估计)、标准误差、Wald统计量、自由度、显著性概率和95%自信区间的上下界。其中越大则该变量效果越显著;
模型拟合信息:给出拟合的信息,-2似然函数值、卡方、自由度和显著性概率(Sigma);
拟合优度:列出卡方检验,自由度和显著性数值;
准R平方:给出参数和参数数值
| 订购用户 | 订购时间 | 年限 | 运行环境 | 版本 |
| 1357****773 | 2019-02-17 04:06:26 | 1年 | Windows | 单机版 |
| 1357****773 | 2019-02-17 04:02:07 | 1年 | Windows | 单机版 |
| 1886****092 | 2018-09-02 10:13:17 | 1年 | Windows | 单机版 |
| 1811****398 | 2018-07-23 13:52:02 | 1年 | Windows | 单机版 |
| 1398****741 | 2017-12-29 09:10:30 | 1年 | Windows | 单机版 |
| 1398****741 | 2017-12-29 08:55:32 | 1年 | Windows | 单机版 |
| 1825****295 | 2017-09-11 15:04:35 | 1年 | Windows | 单机版 |
| 1556****001 | 2017-08-10 23:45:25 | 1年 | Windows | 单机版 |
| 1803****455 | 2017-05-19 03:36:13 | 1年 | Windows | 单机版 |
| 1380****381 | 2017-04-08 01:04:27 | 1年 | Windows | 单机版 |

 加入购物车成功!
加入购物车成功!
