
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构,不断的改善自身的性能。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。这些算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。简而言之,机器学习主要以数据为基础,通过大数据本身,运用计算机自我学习来寻找数据本身的规律,而这是机器学习与统计分析的基本区别。
机器学习主要有三种方式:监督学习,无监督学习与半监督学习。
(1)监督学习:从给定的训练数据集中学习出一个函数,当新的数据输入时,可以根据函数预测相应的结果。监督学习的训练集要求是包括输入和输出,也就是特征和目标。训练集中的目标是有标注的。如今机器学习已固有的监督学习算法有可以进行分类的,例如贝叶斯分类,SVM,ID3,C4.5以及分类决策树,以及现在最火热的人工神经网络,例如BP神经网络,RBF神经网络,Hopfield神经网络、深度信念网络和卷积神经网络等。人工神经网络是模拟人大脑的思考方式来进行分析,在人工神经网络中有显层,隐层以及输出层,而每一层都会有神经元,神经元的状态或开启或关闭,这取决于大数据。同样监督机器学习算法也可以作回归,最常用便是逻辑回归。
(2)无监督学习:与有监督学习相比,无监督学习的训练集的类标号是未知的,并且要学习的类的个数或集合可能事先不知道。常见的无监督学习算法包括聚类和关联,例如K均值法、Apriori算法。
(3)半监督学习:介于监督学习和无监督学习之间,例如EM算法。
如今的机器学习领域主要的研究工作在三个方面进行:1)面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统;2)认知模型,研究人类学习过程并进行计算模拟;3)理论的分析,从理论的层面探索可能的算法和独立的应用领域算法。
K最近邻算法是一种基于类比的分类方法,主要通过给定的检验组与和它相似的训练组进行比较来学习。训练组用n个属性来描述,每个元组代表n维空间上的点。当给定一个未知元组时,K最近邻分类法搜索该模式空间,找出最接近未知元组的k个训练组,并将未知元组指派到模式空间中它的k个最近邻中的多数类中。
其中“最近邻”主要是以距离来度量的,一般使用欧几里得距离度量两个点或元组的距离,也可以使用曼哈顿距离或其他距离;欧几里得距离的主要计算公式如下:
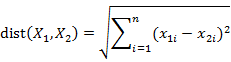
注意:为了防止具有较大初始值域的属性比较小初始值域的属性的权重过大,在计算距离之前,需对每个属性值进行规范化。一般的规划方法有最小-最大规范化,零均值规范化,小数定标规范化等。
最小-最大规范化:将原始数据值映射到[0,1]空间中,假定minA和maxA分别是属性A的最小值和最大值,则规范化的公式为:

零均值规范化:基于属性A的均值和标准差上的规范化方法,具体计算如下:
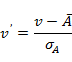
小数定标规范化:通过移动属性A的小数点位置进行规范化,小数点的移动位数依赖于A的最大绝对值。具体计算如下:(其中j是使得MAX(  )<1的最小整数)
)<1的最小整数)
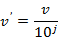
最近邻数K的确定,主要原理是选取产生最小误差率的k值。每次从k=1开始,使用检验集估计分类器的误差率;每次都允许增加一个近邻,重复该过程,选择误差率最小的k值。
二算法背景KNN算法是由Cover和Hart提出来的,是一种懒惰的、有监督的、基于实例的机器学习方法。同时是向量空间模型下最好的分类算法之一。
三相关应用K最近邻算法是一种基本的分类方法,主要对数据进行分类处理。分类时,对新的记录,根据其K个最邻近的训练记录,这K个记录的多数属于某个类,就把该新的记录分为这个类。K值一般选取比较小的数值。通常采用交叉验证法来选取最优的K值。
四参考资料1范明,孟小峰译.数据挖掘:概念与技术.北京:机械工业出版社.2007
2 李航.统计学习方法.北京:清华大学出版社.2012
3Piella G. A regiorr based multiresolution image fusion algorithm. In:ISIF Fusion 2002 Conference.
4Jia Pan, Dinesh Manocha. Bilevel Locality Sensitive Hashing for KNearest Neighbor
五实例
已知二维空间的3个点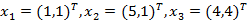 ,试求在P取不同值时,LP距离x1的最近邻点。
,试求在P取不同值时,LP距离x1的最近邻点。
根据K最近邻算法的原理,由于x1和x2只有第二个维度上的值不同,所以P为任何值时,Lp(x1,x2)=4,而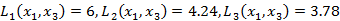 ,
,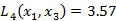 ;于是得到:P等于1或2时,x2是x1的最近邻点;P大于等于3时,x3是x1的最近邻点。
;于是得到:P等于1或2时,x2是x1的最近邻点;P大于等于3时,x3是x1的最近邻点。
输入变量类型:数值型数据
输出结果:得到数据的最近邻,以及最终的分类
七相关条目分类、距离、惰性学习法
八优缺点优点:简单,有效;重新训练的代价低;计算时间和空间训练集的规模;对于数据集的交叉或重叠较多的待分样本集来说,KNN算法比其他算法合适;比较适用于样本容量较大的类域的自动分类,而对样本容量小的类域会产生较大的误分。
缺点:输出的可解释性不强;计算量较大;对数据样本容量相差较大的,应该先进行规范化处理。


