
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。主要研究计算机怎样模拟或实现人类的学习行为,以获取新的知识和技能,重新组织已有的知识结构,不断的改善自身的性能。
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。这些算法是一类能从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。简而言之,机器学习主要以数据为基础,通过大数据本身,运用计算机自我学习来寻找数据本身的规律,而这是机器学习与统计分析的基本区别。
机器学习主要有三种方式:监督学习,无监督学习与半监督学习。
(1)监督学习:从给定的训练数据集中学习出一个函数,当新的数据输入时,可以根据函数预测相应的结果。监督学习的训练集要求是包括输入和输出,也就是特征和目标。训练集中的目标是有标注的。如今机器学习已固有的监督学习算法有可以进行分类的,例如贝叶斯分类,SVM,ID3,C4.5以及分类决策树,以及现在最火热的人工神经网络,例如BP神经网络,RBF神经网络,Hopfield神经网络、深度信念网络和卷积神经网络等。人工神经网络是模拟人大脑的思考方式来进行分析,在人工神经网络中有显层,隐层以及输出层,而每一层都会有神经元,神经元的状态或开启或关闭,这取决于大数据。同样监督机器学习算法也可以作回归,最常用便是逻辑回归。
(2)无监督学习:与有监督学习相比,无监督学习的训练集的类标号是未知的,并且要学习的类的个数或集合可能事先不知道。常见的无监督学习算法包括聚类和关联,例如K均值法、Apriori算法。
(3)半监督学习:介于监督学习和无监督学习之间,例如EM算法。
如今的机器学习领域主要的研究工作在三个方面进行:1)面向任务的研究,研究和分析改进一组预定任务的执行性能的学习系统;2)认知模型,研究人类学习过程并进行计算模拟;3)理论的分析,从理论的层面探索可能的算法和独立的应用领域算法。
PageRank算法用于衡量特定网页相对于搜索引擎中的其它页面的重要程度,从而使得“等级/重要性”的网页会相对排在前面。需要注意的是PageRank重要性级别并不是线性增长的,而是类似于指数的关系。
PageRank算法基本思想:是让链接来“投票”,即网页的重要性由网页间的链接关系所决定的,算法是依靠网页间的链接结构来评价每个页面的等级和主要性,一个网页的PR值不仅涉及到指向它的链接网页数,还涉及指向它的网页的本身重要性。PageRank的计算时基于两个基本假设的,一个是数量假设,即如果一个页面接收到的其它网页的链接数量越多,该网页越重要;另一个是质量假设,即质量高的页面通过链接传递更高的权重。
在初始阶段,通过网页链接关系构建有向图,每个页面设置相同的PR值,通过PageRank的计算公式每次迭代更新当前页面的PR值,通过若干轮递归计算,会得到每个页面的最终的PR值。PageRank算法公式为:
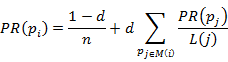
其中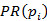 是
是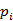 页面的PageRank值,
页面的PageRank值,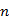 是所有页面的数量,是不同的页面,
是所有页面的数量,是不同的页面,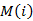 是
是 是
是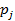 链出页面的数量,
链出页面的数量,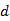 是阻尼系数(任意时刻用户到达某页面后并继续向后浏览的概率),的取值范围为0到1。
是阻尼系数(任意时刻用户到达某页面后并继续向后浏览的概率),的取值范围为0到1。
Pagerank是一种根据网页之间相互链接来计算网页排名的重要算法,主要是以谷歌公司创办人拉里·佩奇的姓来命名。该算法是由Larry Page和Sergey Brin在20世纪90年代后期发明。
三相关应用PageRank算法最广为人知的作用是用于网页排名。但不仅仅只有这个用途,经过多年发展,它也可以应用于神经科学、交通网络等领域中;如用来评估不同大脑区域之间的连接和重要性,以及随着年龄的变化结果会如何改变;也用来预测城市交通流量和人员动向,这有助于提前预测现代交通可能出现的拥堵情况。
四参考资料1维基百科,http://en.wikipedia.org/wiki/Page_rank PageRank
2马克威分析系统使用教程,http://www.tenly.com
五实例举例说明pagerank算法。互联网中的网页可以看作是一个有向图,其中网页是结点,如果网页A有链接到网页B,则存在一条有向边从A指向B,下图为一个简单的示例:
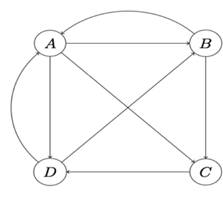
首先计算网页的转移矩阵。网页的转移矩阵是由网页的跳转概率决定的,现已网页A为例来说明跳转概率的计算方式。从图中可以看出,A可任意的跳转到网页B,C,D,故认为跳转概率分别为:1/3,1/3,1/3;所以上图的转移矩阵为:
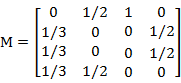
初始时,假设每个网页的点击概率都是相等的,即1/n;于是初始的概率分布就是一个所有值都为1/n的n维列向量V0,用V0去右乘转移矩阵M,于是V1的计算过程为:
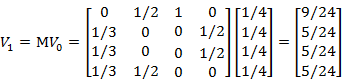
不断计算下去,最终会收敛于某一个定值:
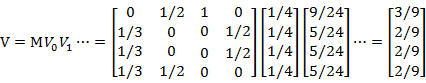
但上述的求解过程要求图是一个强连通的,即从任意网页可以到达其他的任意网页。而一般的互联网上的网页是不满足强连通的特性,不满足强连通的图最终会收敛于某一个定值,通常为0。所以需要做一个平滑处理,即计算公式变为:
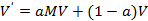
其中a就是查看当前网页的概率,从浏览器地址跳转的概率为1-a。
六输入输出输入数据类型:字符型数据
输出结果:算出所有的网页重要性数值,并得到排名结果
七相关条目谷歌、网页排名、网页链接
八优缺点优点:是一个与查询无关的静态算法,所有的网页重要性值通过离线计算获得;能有效减少在线查询的计算量,极大的降低查询响应时间。
缺点:该算法忽略了查询的主题特征及相关性,导致结果的相关性和主题性降低;旧的页面会比新的页面等级高。


